Most people have had fewer lovers than their lovers have, on average.
The fact that sex is symmetric makes this seem paradoxical. If person X slept with person Y, of course person Y slept with person X. So, how can we possibly expect that a given person has had fewer lovers than their lovers?
The answer is that you are more likely to have sex with someone that has had sex with a lot of people. Let’s say person X has slept with 25 people, whereas person Y has slept with one. Then, [if you choose your partners at random] you are 25 times as likely to have slept with person X than person Y.
This is a form of sampling bias. As individuals, we are more likely to sample [sleep with] those that are more sexually active than others in the population, and this causes us to observe an average higher than the true network average.
In the extreme case, if person Z is a virgin, he or she cannot possibly count towards anyone’s sample to determine the average number of lovers!
This idea of sampling bias is behind the reason “why people experience airplanes, restaurants, parks and beaches to be more crowded than the averages would suggest. When they’re empty, nobody’s there to notice.” [Steven Strogatz, Ref. 1]
The paradoxical phenomena that most people have had fewer lovers than their lovers have also holds for our friendships. Your friends likely have more friends than you – this is the “the friendship paradox” discovered by Scott Feld (Ref. 2). A study analyzing the social network of friends on Facebook (Ref. 3) showed that 93% of people on Facebook have fewer friends than the average of their friends’s number of friends (Ref. 1)!
Similarly, if you are in academia, your coauthors likely have more publications and more citations than you do (Ref. 4); you are more likely to have published with someone who has many publications than someone who has only one.
Not only is the friendship paradox interesting, it is useful. During the H1N1 outbreak in 2009, researchers monitored the health of two disparate sets of students at Harvard University (Ref. 5). The first group consisted of randomly selected individuals. The second group consisted of a group of friends of the individuals in the first group. They found that the progression of the flu epidemic in the second group occurred two weeks earlier than the first! This is because those in the second group are more likely to have more friends than those in the first group by the friends paradox and hence be in contact with more individuals/get the flu earlier. This is a clever sampling method to sense a disease outbreak earlier than observing randomly selected individuals: instead observe the friends of randomly selected individuals (Ref. 5).
Proof
Let’s proove the friendship paradox. A network of friends can be represented as an undirected graph \(G(V,E)\). This graph \(G\) consists of a set \(V\) of vertices, representing people, and a set \(E\) of edges, representing friendships. An edge connects two vertices.
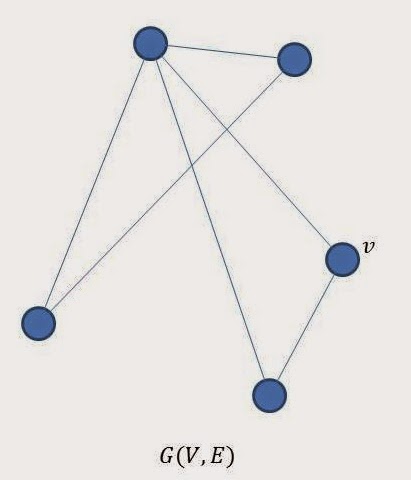
The only notation we need is:
\(d(v)\): the degree of vertex \(v\). The degree is the number of friends that the person represented by the vertex \(v\) has.
\(|V|\): the total number of vertices, i.e., the number of people in the network.
\(|E|\): the total number of edges in our network, i.e., the number of friendships in the network.
What is the expected number of friends a person has in our network? This corresponds to the expected value of \(d(v)\) of a randomly chosen person in the network.
So we sum over all people and count their friends, giving each count a weight \(1/ |V| \) since this is the probability that the given person was the randomly chosen person (the same for everyone in the network).
This can be simplified by the handshaking lemma, which notes that if we loop over all people in the network and add up their count of friends to a total, we will double-count the number of edges in the graph. Thus
Now, I will write the expected value of some characteristic \( x \) of a neighbor of a randomly chosen person in the network as \(\langle x \rangle_n \). This is computed as:
The degree \(d(v)\) appears in the top sum because vertex \(v\) appears as a neighbor \(d(v)\) times. This weight is where the idea of a sampling bias comes into play. The denominator is a normalization. Now it becomes clear that the expected number of friends of a neighbor is:
Using the relation between variance of a random variable \(X\), \(E([X - E(X)]^2)\), the expected value of \(X\), and the expected value of \(X^2\):
we can relate \(\langle d \rangle_n\) to \(E(d)\):
\(\langle d \rangle_n = E(d) + E([d-E(d)]^2) / E(d)\)
This ends the proof by noting the following. The expected number of friends of a randomly chosen individual \(\langle d \rangle_n\) is larger than the expected number of friends in the graph \(E(d)\) by an amount \( E([d-E(d)]^2) / E(d)\), which is greater than or equal to zero. Thus, our friends likely have more friends than we do!
Note that this a general property of a graph, and it is not conditioned on the graph having a particular structure. The only way that \(\langle d \rangle_n = E(d) \) is if the variance \(E([d-E(d)]^2)\) is zero. That is, only if everyone has the same number of friends!
References
[1] S. Strogatz. Friends You Can Count On. New York Times, The Opinion Pages. (2012) http://opinionator.blogs.nytimes.com/2012/09/17/friends-you-can-count-on/?_php=true&_type=blogs&_r=0
[2] Feld, S. L. (1991). Why Your Friends Have More Friends than You Do. AJS,96(6), 1464-77.
[3] Ugander, J., Karrer, B., Backstrom, L., & Marlow, C. (2011). The anatomy of the facebook social graph. arXiv preprint arXiv:1111.4503.
[4] Eom, Y. H., & Jo, H. H. (2014). Generalized friendship paradox in complex networks: The case of scientific collaboration. Scientific reports, 4.
[5] Christakis, N. A., & Fowler, J. H. (2010). Social network sensors for early detection of contagious outbreaks. PloS one, 5(9), e12948.
[6] http://en.wikipedia.org/wiki/Friendship_paradox
[7] S. Kanazawa. Why Your Friends Have More Friends Than You Do. Psychology Today. (2009) http://www.psychologytoday.com/blog/the-scientific-fundamentalist/200911/why-your-friends-have-more-friends-you-do
comments powered by Disqus